
2024-04-07 23:53:42
虚幻引擎(Unreal Engine)是一个用于游戏、设计可视化、电影等领域的先进开发环境。与任何实时应用程序开发一样,在使用虚幻引擎进行开发的过程中对应用程序进行剖析以确保满足性能要求是非常重要的。
本指南旨在为虚幻引擎的剖析和优化提供实用建议。当前版本的性能优化指南侧重于 GPU 性能的剖析和优化。
在剖析开始之前,剖析一节首先会提供一些很不错的建议,然后会介绍可重复的剖析、噪声降低以及确定 CPU 或 GPU-bound等主题。
Radeon? GPU Profiler(RGP)是我们一个强大的剖析工具,可以与虚幻引擎配合使用。这一节介绍了 RGP 解释了如何在 UE4 中使用它,并使用了我们一个优化补丁的示例进行分析。
UE4 中有几个内置的剖析工具,可以作为 UE4 的补充。这一节将介绍这些工具,并重点介绍一些有用的相关功能。
在这一节中可以了解一些关于几何优化、draw call和 GPU 执行的实用建议,其中涉及一些内置工具和工作流。
AMD 有多个团队的主要任务是评估特定游戏或游戏引擎在 AMD 硬件上的性能。这些团队在评估 UE4 产品时经常使用这里介绍的许多方法。在最后一部分,我们会用指导性的视角来看一下通过这些方法能够取得的进展。
在 GPUOpen 上发现更多 Unreal Engine的内容!
在 UE4 中剖析时遇到的第一个问题是应该使用什么样的版本配置。剖析 GPU 时,我们希望 CPU 性能足够快,可以不影响到剖析过程。当然,应该避免使用调试版本进行剖析,因为引擎代码不是在启用优化的情况下编译的。
要注意,开发版本比测试或交付版本有更高的 CPU 开销。但仍然可以方便地对开发版本进行剖析。为了减少开发版本中的 CPU 开销,应关闭 CPU 端任何不必要的开销,并避免在编辑器中剖析。可以使用 -game 命令行参数使编辑器作为游戏运行。下面的命令行是一个示例,其中使用了 -game 并禁用了剖析所不需要的 CPU 开销。

测试版本比开发版本开销更低,同时仍然提供了一些开发者功能。考虑在引擎的 Build.h 文件中为测试版本启用 STATS,以便 UE4 的live GPU profiler(stat GPU)可用。同样,考虑启用 ALLOW_PROFILEGPU_IN_TEST,以便 ProfileGPU 可用。在内置剖析工具一节中将提供有关 stat GPU 和 Profile GPU 的更多详细信息。
独立可执行文件的测试版本需要 cooked 内容。如果您需要在剖析时进行迭代,但希望测试版本既有较低的 CPU 开销,那么可以考虑使用“cook on the fly (COTF)”。例如,着色器迭代对于 COTF 测试版本就是可能的。
您的版本现在已经准备好进行剖析了,在开始前您还要检查一些事情。首先,确保禁用了帧速率平滑(Frame Rate Smoothing)。此功能从 UE4.24 开始默认禁用,但最好再检查一下。在编辑器中,您可以通过 Edit(编辑)->Project Settings(项目设置)…->Engine(引擎) –>General Settings(常规设置)->Framerate(帧率) 来检查,如下所示:
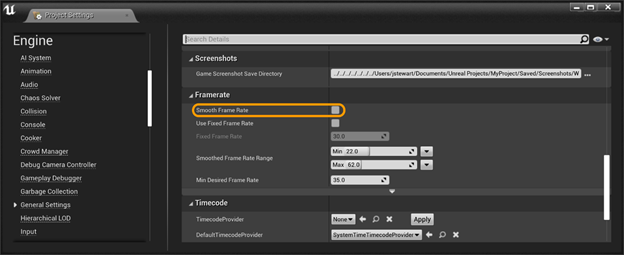
或者,您可以确保 bSmoothFrameRate 在 Engine\\Config\\BaseEngine.ini 和您项目的 DefaultEngine.ini 中出现的任何地方都设置为 false。您也可以将 bForceDisableFrameRateSmoothing=true 添加到您项目 DefaultEngine.ini 的[/Script/Engine.Engine]部分。
然后,关闭 VSync。一种方法是使用 -novsync 命令行参数.将其添加到我们前面的示例中,得到以下结果:

最后,运行您的版本并在日志文件中验证分辨率。分辨率当然是影响 GPU 性能的一个非常重要的因素,有必要验证一下它是否符合您的预期。打开该版本的日志文件并查找如下所示的行:

本节包含一些在剖析时获得一致结果的小建议,以便您可以更好地确定潜在的优化是否确实提高了性能。
剖析的一种方式是转到您所在级别中的同一位置。
一个玩家出生点(Player Start)actor 可用于在启动时直接生成到一个特定的位置。可以通过编辑器将其拖入场景中。
如果您无法在编辑器模式下更改场景,或者想在游戏中传送,那您可以使用 UCheatManager BugIt 工具。注意:BugIt 工具仅在非交付版本中可用。
使用 BugIt 传送:
这个 BugItGo 命令可以粘贴到控制台中,来从任意位置传送到当前位置。
在尝试优化工作负载的执行时间时,我们需要确切地测量出某一工作负载所花费的时间。这些测量的噪声应尽可能小。否则我们无法判断它运行得更快是因为我们的优化,还是因为其他原因,如随机数生成器决定生成更少的粒子。
UE4 有一些内置功能来实现这一点-benchmark 命令行参数可以使 UE4 自动更改某些设置,对剖析更友好。-deterministic 参数可以使引擎使用固定的时间步长和固定的随机种子。然后,您可使用 -fps 设置固定时间步长,并使用 -benchmarkseconds 使引擎在固定的时间步长数后自动关闭。
下面是将这些参数在 Infiltrator demo 测试版本中使用的示例:

在上面的例子中,benchmarkseconds 并不是时钟时间(除非 demo 的每一帧正好以60 fps 运行)。而是使用1/60=16.67毫秒的固定时间步长运行211×60=12660帧。这意味着,如果您的项目设置为在启动时运行相机飞行,它将使用固定的时间步长和固定的随机种子往前飞行。然后在固定帧数后自动关闭。这对于收集您这一关卡的可重复平均帧时间数据非常有用。
另一种有助于降低剖析结果中噪声的技术是以固定时钟运行。大多数 GPU 都有默认的电源管理系统,在空闲时切换到较低的时钟频率以节省功耗。但这会以较低的功耗换取性能,并会在基准测试中引入噪声,因为在应用程序数次运行间时钟的尺度可能不尽相同。您可以固定 GPU 上的时钟以减少此差异。 有许多第三方工具可以执行此操作,但 Radeon GPU Profiler 附带的 Radeon Developer Panel 在“Applications(应用程序)”下有一个“Device Clocks(设备时钟)”选项卡,可用于在 AMD RDNA? GPU 上设置稳定的时钟,如下所示:
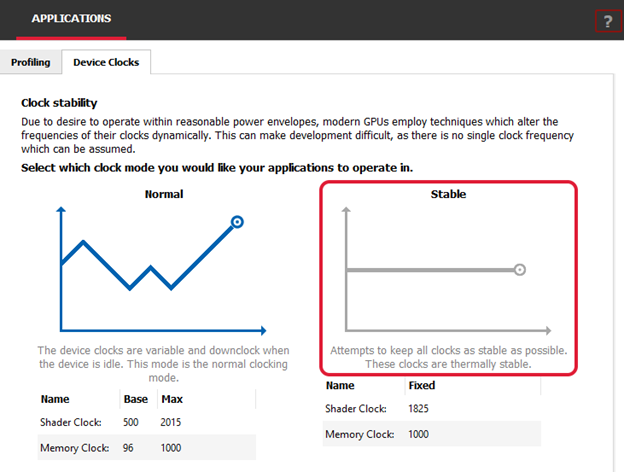
还是来说说如何减少 UE4 中的可变性吧,您可能会发现有些东西不依照 -deterministic 命令行参数中的固定随机种子。在 Infiltrator demo 中一些粒子就是这种情况。这些粒子在我们的基准测试中引起了明显的噪音。
降低粒子噪声的解决方案是让随机数生成器使用固定的种子。仅需单击两次您就可以使粒子具有确定性:
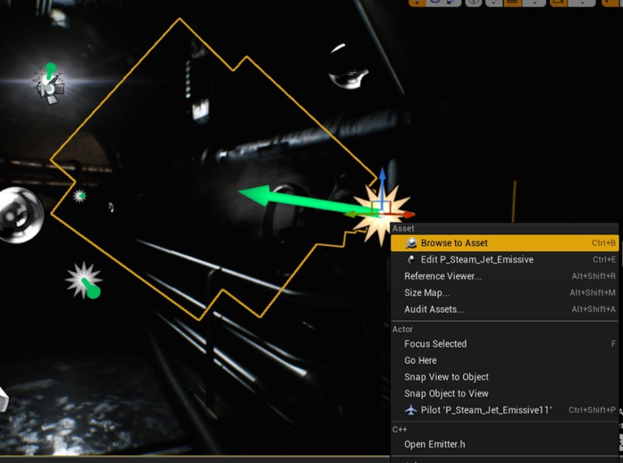
1-右键单击粒子发射器,然后单击“Browse to Asset(浏览到资源)”
2-在 Content Browser(内容浏览器)中选择发射器资源后,右键单击它,然后选择“Convert To Seeded(转换为种子)”
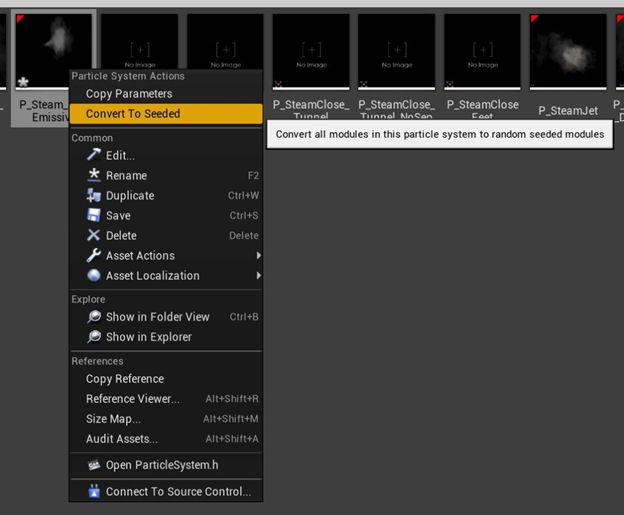
就是这样!也可以在 Content Browser (内容浏览器)中选择所有发射器,一次性进行转换。这样操作后,噪音将大大降低,并且可以很容易地评估您的优化。
注意:如果使用的是 Niagara 粒子,请在 UE4.22 官方发布页面中查找“Deterministic Random Number Generation in Niagara”:https://www.unrealengine.com/en-US/blog/unreal-engine-4-22-release
优化一个效果需要实验许多次,每一次迭代都需要时间。我们需要重建游戏、烘焙内容等。UE4 的功能如“cook on the fly (COTF)”可以帮助解决这一问题。但将要优化的效果或技术隔离到一个小应用程序中也很有用。
要是能轻松生成这样的 app 就好了!幸运的是,Unreal 为此提供了一个功能,名为 Migrate(迁移)。它可以提取某个资源及其所有依赖项,并将其导入到任何其他项目中。为了创建一个小应用程序,我们就可以用此功能将这个效果移植到一个空的项目中。
迁移资源的官方文档在此:https://docs.unrealengine.com/en-US/Engine/Content/Browser/UserGuide/Migrate/index.html
在 UE4 中开始使用性能剖析时,了解在目标平台上运行时的主要性能瓶颈非常重要。瓶颈是位于 CPU 还是 GPU 上可能会将性能剖析导向截然不同的两个方向。
使用 Radeon Developer Panel(RDP)进行性能捕获后,这些详细信息可从 Overview(概览)->Frame Summary view(帧摘要视图)中获得。
下面所展示的,是通过向 UE4 添加使 CPU 繁忙的工作所创建出的一个 CPU-bound的极端案例,在其之后是一个 GPU-bound的场景。
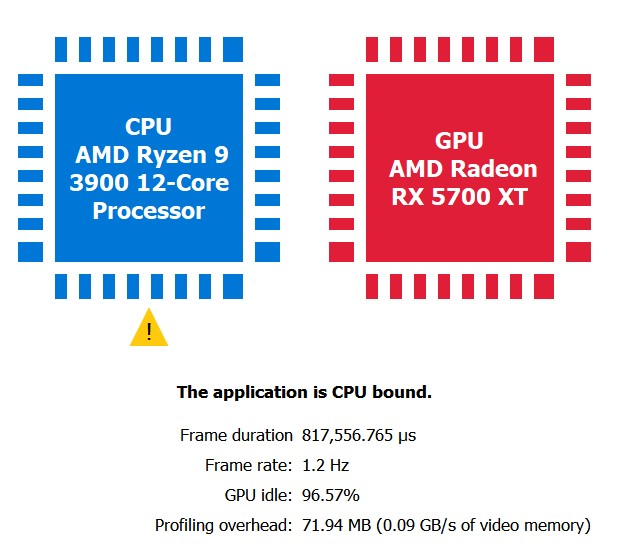
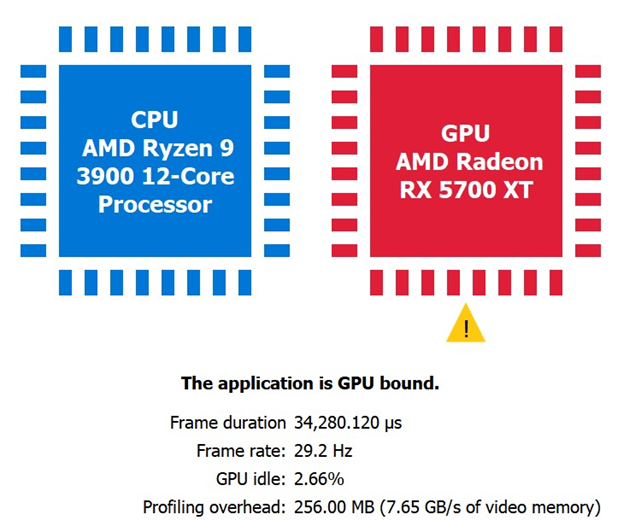
一个检查应用程序是否确实 CPU-bound的可用性测试是提高渲染分辨率。例如,如果通过将 r.ScreenPercentage 从100调整为150来增加 GPU 工作负载,并且 RGP 显示与以前相同的 CPU-bound结果,这就明确表明了该应用程序是完全 CPU-bound的。
一旦我们确定是 GPU-bound还是 CPU-bound,我们可能会决定用 RGP 进一步诊断(如果我们是 GPU-bound),或者切换到其他工具,如 AMD μProf(如果我们是 CPU-bound)。如前所述,这个版本的指南关注的是 GPU,因此我们现在将讨论如何确定 GPU 的时间耗费在哪里。
Radeon? GPU Profiler(RGP)是在 RDNA GPU 上进行剖析的一个非常有用的工具。要在 UE4 中使用 RGP 捕获,我们必须在 D3D12 RHI 或 Vulkan RHI 上运行 UE4。本指南将使用 D3D12 作为示例。您可以使用 -d3d12 命令行参数运行 UE4 可执行文件或在编辑器中更改默认 RHI 来调用 D3D12 RHI: Edit(编辑)->Project Settings…(项目设置)->Platforms(平台)->Windows(窗口)->Default RHI to DirectX 12(默认 RHI 到 DirectX 12)。
在使用 RGP 捕获之前,在 ConsoleVariables.ini 中取消注释以下行:D3D12.EmitRgpFrameMarkers=1。这确保了任何包裹在 SCOPED_DRAW_EVENT 宏中的 UE4 代码都在 RGP 中显示为有用的标记。
注意:如果使用的是测试版本,请在 Build.h 中 ALLOW_CHEAT_CVARS_IN_TEST,以便在测试版本中使用 ConsoleVariables.ini,或是在项目的 DefaultEngine.ini 中添加一个[ConsoleVariables]部分:

本节使用我们在 GPUOpen 上的一个 UE4 优化补丁来演示利用 RGP 进行剖析。此示例将帧时间减少0.2毫秒(在Radeon 5700XT 上测试 4K)。0.2毫秒可能看起来不太多,但您的游戏如果是以60fps为目标的话,0.2毫秒大概是您60 FPS 帧预算的1%。
如果您已经集成补丁程序并希望重现本节中的结果,请首先使用控制台禁用优化:r.PostProcess.HistogramReduce.UseCS 0
使用 RDP 进行性能捕获后,可以在 RGP 的 Events(事件)->Event Timing(事件计时)视图中获得这些详细信息。如果要发射 RGP perf 标记,则可以通过搜索“PostProcessHistogramReduce”快速导航到我们正在研究的标记。

我们可以看到 DrawIndexedInstanced() 调用需要211微秒才能完成。我们可以做得更好!
要检查 GPU 上运行的像素着色器的详细信息,右键单击draw call,选择“View in Pipeline State(在管线状态下查看)”,然后在管线中单击“PS”。
“Information(信息)”选项卡显示我们的像素着色器仅运行1个 wavefront 且仅占用该 wavefront 的32个线程。在 GCN GPU 和更新架构的 GPU 上,这种类型的 GPU 工作负载将在“partial(部分) wave”中执行,这意味着 GPU 没有得到充分利用。
“ISA”选项卡将为我们提供在 GPU 硬件上执行的确切着色器指令以及 VGPR/SGPR 占用率。“ISA”视图对其他优化也很有用,比如此处未涉及的标量化(https://flashypixels.wordpress.com/2018/11/10/intro-to-gpu-scalarization-part-1/)
查看此着色器的 HLSL 源文件(PostProcessHistogramReduce.usf)可见,如果要最大化使用 GPU 硬件性能并消除任何 partial wave 现象,需要并行执行一个很长的循环。我们通过切换到计算着色器并利用 LDS(本地数据存储/组共享内存)来实现这一点,LDS 是支持 Shad Model 5 的现代 GPU 上可用的一个硬件功能。
接下来,我们可以启用优化以查看性能影响:r.PostProcess.HistogramReduce.UseCS 1
使用 RDP 进行另一次性能捕获并返回 RGP 中的“Event Timing(事件计时)”视图后:

调度所需时间为7微秒,性能提升高达96%!所花费的大部分时间在barrier处,这是不可避免的,因为我们的 PostProcessHistogramReduce pass 与先前的 PostProcessHistogram pass 具有数据依赖性。
这种性能提升的原因是执行了更短的循环,利用 LDS并使用 load(加载)而不是 sample(采样)(图像加载在 RDNA 上更快)。ISA 视图向我们展示了在 ds_read* 和 ds_write* 指令中发生的新 LDS 工作。
1-系统配置:Ryzen 9 3900,32GB DDR4-3200,Windows 10,Radeon Software Adrenalin 2020 20.2.2版,3840×2160分辨率
本节介绍内置的 UE4 剖析工具。这些可以作为 RGP 分析的补充。
UE4 stat 命令
这里是记录了所有 stat 命令的列表:https://docs.unrealengine.com/en-US/Engine/Performance/StatCommands/index.html
从上表中删除的最重要的命令:
GPU Visualizer:stat 命令非常适合实时查看性能,但假设您在场景中发现了 GPU 瓶颈,并希望更深入地挖掘单帧捕获。ProfileGPU 命令允许您在 GPU Visualizer 中展开一帧的 GPU 工作,这对于需要来自引擎的详细信息的情况非常有用。一些例子:
对于 GUI 版本,请在运行 ProfileGPU 前将 r.ProfileGPU.ShowUI 设置为1。更多详情请查看官方文档:https://docs.unrealengine.com/en-US/Engine/Performance/GPU/index.html
我们强烈建议使用 RGP 代替 GPU Visualizer 作为 RDNA GPU 的剖析工具。RGP 能和上文中的例子有相同的工作流程。使用 RGP 可以通过更精确的计时和底层 ISA 分析获得深入的 GPU 性能捕获。
FPS 图表
用于长时间内的基准测试,获取持续时间内的 stat 单位时间。结果放置在 .csv 文件中,可在 CSVToSVG Tool 中绘制:https://docs.unrealengine.com/en-US/Engine/Performance/CSVToSVG/index.html
控制台命令切换:startfpschart 和 stopfpschart
本节提供了在 UE4 中优化内容和着色器的一般建议。
良好的优化意味着避免过度细化几何体,几何体会在屏幕空间中产生小三角形;总之,要避免产生小三角形。这意味着使几何处于检查状态是实现性能目标的一个重要因素。通过编辑器访问的“Wireframe(线框)”视图模式是初探场景中对象几何复杂性的一个上佳工具。请注意,较高的半透明度会降低线框视图模式的速度,并使其看起来更拥挤、更无用。RenderDoc 也显示线框。
UE4 中的 LOD 是一个重要的工具,以避免在远处观察网格时出现大量的微小三角形。详情请参阅官方文档:https://docs.unrealengine.com/en-US/Engine/Content/Types/StaticMeshes/HowTo/LODs/index.html
UE4 可计算场景可见性,以剔除将不会出现在帧最终图像中的对象。但是,如果剔除后的场景仍然包含数千个对象,draw call 就可能成为一个性能问题。即使我们渲染具有低多边形数的网格,如果有太多的 draw call,也会由于为 GPU 设置每个 draw call 相关的 CPU 端成本而成为主要的性能瓶颈。每个 draw call UE4 和 GPU 驱动程序都要工作。
但减少 draw call 是一种平衡手法。如果决定通过使用几个较大的网格而不是许多较小的网格来减少 draw call,则会失去从较小模型获得的剔除粒度。
我们建议至少使用 Unreal Engine 4.22版,以获得具有自动实例化的网格绘制重构。
UE4 的 Hierarchical Level of Detail(HLOD)系统可以在一定距离内用单个网格替换多个静态网格来减少 draw call。具体请查看官方文档:https://docs.unrealengine.com/en-US/Engine/HLOD/index.html
“stat scenerendering”命令可用于检查场景的 draw call 数。
我们在本指南前面的 RGP 和 UE4 示例一节中介绍了一个优化 GPU 执行的示例。我们将在 GPUOpen UE4 优化案例研究一节中介绍另一个示例。本节介绍一些可优化 UE4 中 GPU 执行的内置工具和工作流。
优化视图模式
UE4 编辑器有许多可视化工具来辅助调试。调试性能中最值得注意的就是 “Optimization Viewmodes”(优化视图模式)。有关不同模式的详细信息,请参阅官方文档:https://docs.unrealengine.com/en-US/Engine/UI/LevelEditor/Viewports/ViewModes/index.html
AMD 有多个团队的主要任务是评估特定游戏或游戏引擎在 AMD 硬件上的性能。这些团队在评估 UE4 产品时经常使用本文档中介绍的许多方法。在本节中,我们将有指导地探讨其中一些方法的进展情况。本节(以及其他部分)中所讨论的优化结果的简单整合都可以在此处获得。
评估在 DX12 上运行的 Unreal Engine 的 Radeon GPU Profiler (RGP) 跟踪是此优化生命周期的开始。在 RGP 中开始任何评估之前,要确保 UE4 配置为发射 RGP 帧标记。这极大地简化了在 RGP 剖析文件中导航大量数据的任务,并且可以通过分配 CVar 值:D3D12.EmitRgpFrameMarkers=1,来完成 DX12 的任务。
在 RGP 的“OVERVIEW(概览)”选项卡下有一个面板,显示了消耗最高事件的排序列表。在一个捕获中,在此排序下紧挨着的两个特定事件突出显示为优化潜在目标:

这一对事件被选中有几个原因:
在我们开始尝试优化此事件之前,我们应该先确保我们了解其作用及其作用方式。我们将通过检查 Renderdoc 中的操作来实现这一点。在 Renderdoc 中开始任何调试分析之前,请确保已将 UE4 配置为保留着色器调试信息。如果此信息可用,Renderdoc 将提供更多关于给定事件执行的上下文。您可以通过通过指定 CVar 值:r.Shaders.KeepDebugInfo=1,来实现这一点。如果是首次启用此值,请做好准备,在下次启动 Unreal 时需要等待一段漫长的时间直到着色器编译完成。
在 RGP 的“Most expensive events(消耗最高事件)”面板中,右键单击所需事件并选择“View in Event timing(在事件计时中查看)”将打开“EVENTS(事件)”选项卡“Event timing(事件计时)”面板,并将您直接传输到目标事件。
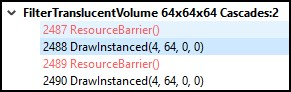
在此视图中,我们可以看到事件是名为 FilterTranslucentVolume 调试区域的一部分,我们将使用此信息在 Renderdoc 中定位此事件。
在此场景的 Renderdoc 捕获中,在“Event Browser(事件浏览器)”中搜索 Renderdoc 可直接将我们传送到目标事件的 Renderdoc 展示界面。
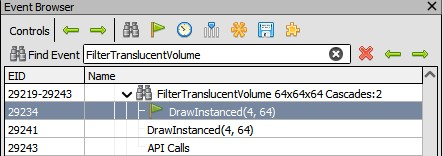
在保留调试信息的情况下,我们可以通过单击“Pipeline State(管线状态)”选项卡中的“stage data(阶段数据)”面板顶部的“View(查看)”按钮,直接查看完整的 HLSL 源文件,其中包含所有相关的 #include 内联函数和所有相关的 #if,它们已经为渲染管线的每个阶段进行了评估。如果需要,我们还可以查看目标着色器的源文件中的入口点或查看原始反汇编。
对与管线各阶段关联的源文件进行检查后表明,此事件正在从 64x64x64 的 3D 纹理中读取像素,并将结果平均到另一个 64x64x64 的 3D 纹理中,一次一个切片。像素着色器根据当前绘制的实例 ID 在输入和输出纹理中选择适当的切片。顶点着色器和几何着色器不对输入顶点执行矩阵操作。
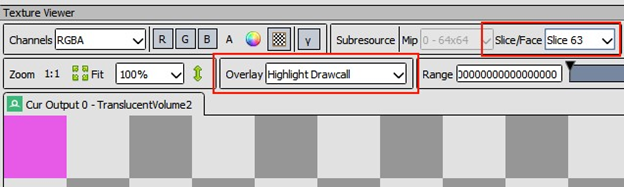
一个4顶点绘制与一个不执行矩阵操作的顶点着色器的组合表明,这个操作只是将一个正面的四方形绘制为一个三角形条。像素着色器的其他上下文表明,四方形可能旨在覆盖输出 3D 纹理的单个切片的整个64 × 64区域。检查 Renderdoc 中的“Input Assembler(输入汇编)”阶段,特别是“Mesh View(网格视图)”可视化工具,可验证此事件绘制第一个实例的这些预期。“Texture Viewer(纹理查看器)”选项卡中每片“Highlight Drawcall(高亮 draw call)”的 64×64 粉色区域证实了其他各个实例以及整个输出 3D 纹理空间的信息。
有了这些信息,我们终于可以开始尝试优化了。我们通过返回 RGP 中的“Event timing(事件计时)”面板来启动这个过程。选择目标事件,然后切换到面板顶部的“Pipeline State(管线状态)”选项卡,可提供有关此绘制的其他信息。选择 PS 管线阶段会带来关于像素工作负载的额外信息。
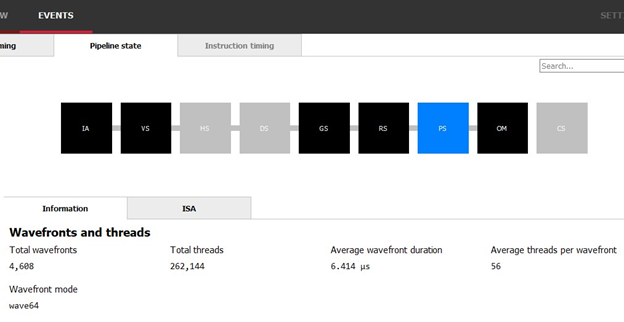
在这里,我们可以看到共262144个唯一的像素着色器调用,这与我们在 Renderdoc 中检查事件所得的预期一致:64x64x64 的 3D 纹理中的每个像素都应该被输出,而 64x64x64=262144。此处提供的其他信息也值得关注。AMD GPU 将工作规整到相关的组里,这些组称为 wavefront。该事件的 wavefront 模式是wave64,因此在理想情况下,每个 wavefront 应有64个线程;我们在该事件期间的平均 wavefront 中仅实现了这些线程中的56个。这一现实意味着我们或许在浪费可能的周期,这也代表了存在潜在的优化机会。这种潜在机会能否被实现,完全取决于我们为什么不能实现每个 wavefront 用满64个线程。
在高层级上,将相关工作组织到 wavefront 中往往会通过 SIMD 产生高效率的执行。在这种情况下,这样的组织也有一个缺点。由于使用了两个单独的三角形渲染四边形来渲染四方形,因此为每个与三角形关联的像素工作都生成了单独的 wavefront。一些在三角形边界附近的像素最终被组织成 partial wavefront,其中一些线程被禁用了,因为它们表示的像素在活动三角形之外。每个 64×64 输出区域中相对较小的一片加剧了这种现象在整个工作中所占的百分比。有完整的文件详细说明了这一现象背后的原因。我们推荐您阅读一些 AMD 白皮书以获取更多信息。
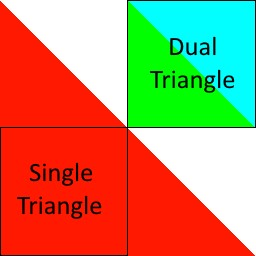
从这之后,提高组织现有像素工作效率的解决方案就相对简单了。由于问题是两个三角形之间存在较大的像素空间边界导致的,因此消除该边界就能解决问题。在 Renderdoc 中检查此事件时,我们了解到渲染目标的每个切片所表示的整个 64×64 区域正在输出。在到达渲染管线的像素着色器阶段之前,就将会落在该区域之外的像素丢弃,并且我们可以利用这一事实来重新考虑如何覆盖该区域。图中展示了我们如何用一个三角形完全覆盖这个区域(以及一些其他区域)。虽然双三角形所提供的精确覆盖乍看似乎更严谨,但我们迄今收集的数据表明,消除这两个三角形之间的边界最终可能会更有效。
理论上,这样的重构还有个可能的好处。在检查过程中,我们注意到像素着色器主要是对预生成的纹理进行采样,并将结果平均到输出渲染目标中。这其中只进行了很少的计算工作,而且这个内核的大部分开销应该表现为等待内存访问。消除第二个三角形将改变该四方格子的光栅化模式,因为单独产生的 wavefront 不再局限于覆盖单个三角形,即输入和输出区域的一半。去掉这一条件使 wavefront 可以不受阻碍地连续对压缩内存的整个块或未压缩内存的整个扫描线进行操作。这样可能会使空间缓存对内存访问更有助益,因此我们希望总体缓存利用率能有所提高。
有了优化计划,就该执行了。我们再次使用 RGP 和 Renderdoc 中的调试区域来帮助我们确定在 Unreal Engine 中进行此重构的适当位置。在源代码中搜索 FilterTranslucentVolume 会产生许多结果,其中包括调用了宏 SCOPED_DRAW_EVENTF 的那个。这个宏生成了我们在 Renderdoc 和 RGP 中看到的调试标记;我们这就找到了入口点。检查该函数的源最终会引导我们到 VolumeRendering.cpp 文件中的函数 RasterizeToVolumeTexture,在那里我们会发现两点:
现在我们已经迈出了坚实的一步,实施计划的其余部分将在这里提供的补丁中进行。
在开始测量性能增益之前,务必确保优化在彻底且正确地进行。跳过该步骤Renderdoc 仍然是这里的首选工具。我们已经评估且理解了实施计划,所以自然知道在 Renderdoc 优化后要检查的内容。我们没有涉及任何着色器的修改,因此这方面不会产生问题。我们需要确保新三角形的输出完全覆盖 3D 纹理的每个切片、经过了隐面剔除,并具有适当的纹理坐标。Renderdoc 中的“Mesh View(网格视图)”工具和“ Texture Viewer Overlays(纹理查看器覆盖)”可快速完成这些验证。
要评估的第一个也是最重要的结果是,我们要观察到相关事件的性能节约。通过返回 RGP 中“EVENTS(事件)”选项卡的“Event timing(事件计时)”面板,然后单击面板右上角的“Show details(显示详细信息)”按钮,可以轻松地处理此任务。这将展开详细信息窗格,其中包括单个任务的总持续时间。在这种情况下,我们可以看到大约减少了20微秒。
之前——双三角形四方格子(4顶点)
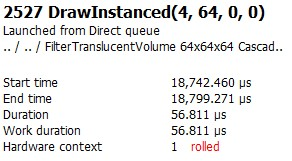
之后——单个三角形四方格子(3顶点)
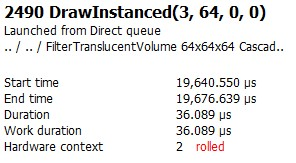
因为我们之前发现这一事件似乎发生了两次,我们也很容易证实有两次20微秒的节省。太好了!
正确理解为何变快也是很有价值的。有时,在解决想解决的问题未果时,会出现额外的节省。在本次评测中,我们将同时使用 RGP 和 Renderdoc。由于我们已经使用 RGP 来查看 wavefront 低效的线程利用率,因此可以很容易地返回到“EVENTS”选项卡的“Pipeline state”面板中的视图,并验证像素着色器工作中每个 wavefront 的平均线程数是否增加。它们平均线程都有64,而这正是我们想要看到的。这表明,作为此操作的结果,我们已经成功地消除了此事件的所有 partial wavefront。
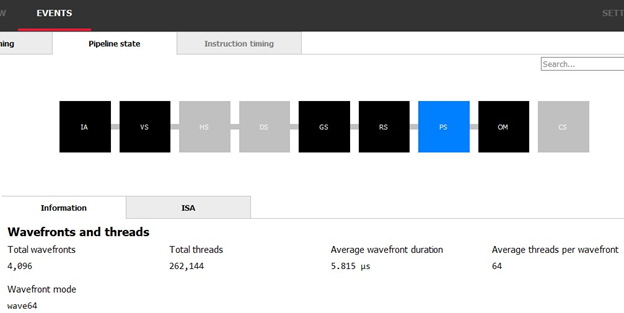
我们还察觉到了一个迹象,即我们理论上对缓存利用率的的改进可能有了进展。除了产生更少 wavefront 且更有效地组织 wavefront 之外,wavefront 的平均持续时间也同时从6.414微秒减少到5.815微秒。然而,这个数据并不可靠,不能证明什么。为了获得缓存利用率提高的证据,我们可以检查 AMD 专属的性能计数器。
遗憾的是,在撰写本文时 RGP 还不支持性能计数器。但最新版本的 Renderdoc 支持,其中包括 AMD 专属的性能计数器。我们可以在场景的 Renderdoc 捕获中检查此信息,方法是选择 Window(窗口)> Performance Counter Viewer(性能计数器查看器)来打开相关选项卡。 单击“Capture counters(捕获计数器)”按钮将打开一个对话框,其中包含一个 AMD 下拉菜单,我们可以从中选择所有缓存级别的缓存命中和未命中计数器。
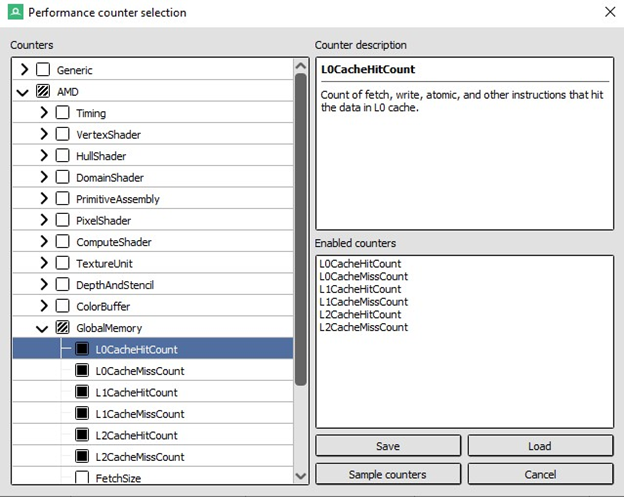
单击“Sample counters(示例计数器)”按钮后,Renderdoc 将在启用计数器的情况下重新渲染场景。在“Performance Counter Viewer(性能计数器查看器)”选项卡中的“Capture counters(捕获计数器)”按钮旁,有一个“Sync Views(同步视图)”按钮。确保启用了“Sync Views(同步视图)”,然后在“Event Browser(事件浏览器)”中选择目标事件。如果您已经选择了目标事件,请选择其他事件,然后返回。“Performance Counter Viewer(性能计数器查看器)”选项卡将自动滚动到包含目标事件的计数器所在的行并突出显示。
通过将缓存命中计数和缓存未命中计数相结合,我们可以展示有效缓存利用率在成功的缓存请求中的百分比。这一操作是在 excel 中完成的,原始数据如下所示:
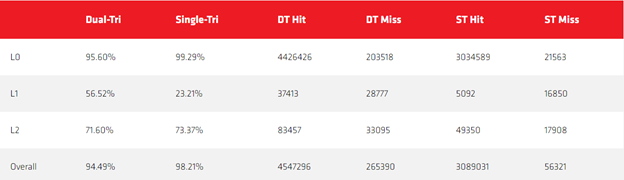
从这些结果中可以看到显著的整体改进,并显示出在应用这种优化之后非常优秀的 L0 利用率。性能结果分析表明这种优化在所有标准上都是成功的。
Unreal Engine 是一个庞大而复杂的代码库,有时很难做出不产生副作用、有针对性的更改。测试范式总是随不同项目、不同优化而变化,但可以记住一些建议:
正确执行这一步总是很重要,有时可以增加优化的相对值。对这里讨论的单个三角形优化执行此操作时,我们发现了许多超出最初的那对绘制,这些绘制受到了此优化的积极影响。预期总节省量也相应增加。

